
1. 소개
최근에 필자는 하스켈이라는 언어를 공부하고 있다. 함수형 프로그래밍에 대한 깊은 이해를 위해서 겉핥기를 하고 있는데, 최근 정렬과 관련하여 궁금한 점이 생겨서 이렇게 정리하게 되었다. 참고로 이 포스팅에서 하스켈에 대해 깊이 알 필요는 없으며 함수형 언어라고만 생각해도 이해하는 데에는 지장이 없다.
Data.List는 리스트 정렬을 위한 sort 함수를 제공한다. 이 함수는 퀵정렬을 쓰지 않는다. 대신 병합 정렬이라는 알고리즘의 효율적인 구현을 사용한다.
- WikibooksHaskell -
지금까지 공부하기로는 대부분의 언어에서 정렬 함수는 퀵정렬(Quick Sort)을 활용하고 있다고 배웠다. 심지어 같은 시간복잡도를 가지는 병합정렬에 비해 일반적으로 더 빠르며, 면접 준비에서도 그렇게 대비하였다. 본 내용에 들어가기에 앞서 병합정렬(Merge Sort)과 퀵정렬(Quick Sort)에 대해 간단하게 짚고 넘어가자. 만약 이 두 정렬을 모르고 있다면 필자의 병합정렬에 대한 글과 퀵정렬에 대한 글을 먼저 읽어봐도 좋겠다.
* 병합 정렬
- 병합 정렬은 데이터를 계속 반으로 쪼개고, 다시 합치며 정렬을 하는 방식이다.
1 9 8 4 3 5 2 7
...
1 | 9 | 8 | 4 | 3 | 5 | 2 | 7 # 가장 작은 단위 까지 나눠짐
1 9 | 4 8 | 3 5 | 2 7 # 한 개씩 정렬되어 병합
1 4 8 9 | 2 3 5 7 # 두 개씩 정렬되어 병합
1 2 3 4 5 7 8 9 # 네 개씩 정렬되어 병합
- 위와 같은 재귀의 과정을 거치며 평균 시간 복잡도는 nlogN을 갖게 된다. 초기 정렬 여부와 관계 없이 나누고 병합하는 과정은 반드시 동작하므로 상한과 하한 모두 nlogN 의 시간복잡도를 갖는다.
- 병합정렬은 각 단계별로 메모리가 필요하므로 다른 정렬에 비해 필요한 메모리가 클 수밖에 없다.
* 퀵 정렬
- 퀵 정렬은 병합정렬과 마찬가지로 분할 정복 알고리즘을 활용하고 있지만 피벗을 사용한 비균등 분할정렬이다.

- 위와 같은 배열이 있다면 하나를 "피벗"으로 선택하고, 이를 기준으로 정렬을 시작한다. 여기서는 가장 첫 번째 값을 선택하였다.
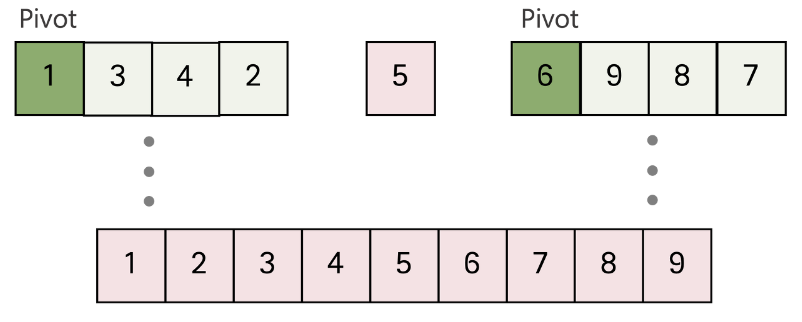
- 퀵 정렬은 이상적인 경우 nlogN이다. 이유는 분할이 이상적으로 이루어질 경우, 정확히 절반씩 나누어지므로 호출의 깊이가 logN이 되기 때문이다.
- 그러나 이미 정렬된 배열의 경우 호출의 깊이가 N이 되므로 시간복잡도가 N^2이 될 가능성도 존재한다. 그럼에도 병합정렬보다 빠르다고 하는 이유는 적당히 랜덤한 피벗을 잘 고르기 때문이고, 피벗은 선택된 순간부터 이후 연산에서 제외되기 때문이다. 따라서 같은 nlogN이더라도 조금 더 빠르다.
- 추가적으로 퀵 정렬은 in-place 정렬 수행이 가능하다. 이는 새로운 배열을 생성하지 않는 방식을 의미하므로 메모리 사용량을 아낄 수 있다.
2. 병합정렬을 쓰는 이유
위의 내용만을 봤을 때 퀵정렬이 아닌 병합정렬을 쓸 이유는 전혀 없어 보인다. 하지만 하스켈이 병합정렬을 쓰는데에는 분명히 이유가 있다. 이는 하스켈이 "함수형 언어" 라는데에서 찾을 수 있다.
* 적합한가
- 일반적으로 우리가 사용해왔었던 명령형 언어들은 퀵 정렬을 in-place로 수행한다. 하지만 이는 함수형과 맞지 않다. 순수함수를 유지하기 위해 우리는 변동없는 리스트를 유지해야한다. 이는 본질적으로 복사를 하며 구현할 수 밖에 없다. 억지로 in-place 정렬 수행을 할 수 있다고는 하나 성능이 그렇게 좋지 않다고 한다.
- 즉 side effect를 발생시키지 않고 기존 데이터를 변경하지 않는 병합정렬이 함수형 언어에 더 적합하다.
* 안정적인가
- 위에서 언급했듯이 병합정렬은 항상 nlogN을 유지하는데 반해, 퀵정렬은 n^2이 될 경우도 존재한다. 따라서 안정적인 속도를 내기 위해 병합정렬을 택할 수 있다.
- 하지만 이때, 다른 언어처럼 적절히 피벗을 설정하면 되지 않냐고 반박할 수 있다. 이는 아래에서 알아보자.
* 피벗
- 실제로 하스켈은 예전에 퀵정렬을 제공했다고 한다. 이 때 랜덤 피벗이 아닌 첫 번째 값으로 피벗을 설정하였는데, 거의 정렬된 배열을 받으면 n^2이 될 수 밖에 없었다.
- 왜 다른 언어처럼 랜덤 피벗을 설정하지 않았을까. 함수형 언어는 사이드이펙트를 발생시키지 않아야 하므로 '랜덤'이라는 것은 큰 문제가 될 수 있다.
- 무작위 값을 관리하는 것이 문제라면 정렬 함수 내부에 랜덤 값 생성을 넣고 사이드 이펙트를 제거할 수 있지 않을까. 아쉽게도 이렇게 할 경우 결과적으로 복사본을 만들어야 하므로 in-place 정렬이 불가능해진다.
- 즉 '랜덤'도 좋지 않을 뿐더러 한다 하더라도 퀵 정렬의 장점인 in-place 정렬을 수행할 수 없게 된다.
* 속도
- 위에서 말했듯 하스켈에서는 퀵 정렬을 제공하던 때가 있었다고 한다. 하지만 변경된 이유를 주석에서 찾을 수 있었다.
- Data.OldList의 문서에 따르면 아래와 같은 내용이 나오고 있다.
Quicksort replaced by mergesort, 14/5/2002.
From: Ian Lynagh <igloo@earth.li>
I am curious as to why the List.sort implementation in GHC is a
quicksort algorithm rather than an algorithm that guarantees n log n
time in the worst case? I have attached a mergesort implementation along
with a few scripts to time it's performance, the results of which are
shown below (* means it didn't finish successfully - in all cases this
was due to a stack overflow).
If I heap profile the random_list case with only 10000 then I see
random_list peaks at using about 2.5M of memory, whereas in the same
program using List.sort it uses only 100k.
Input style Input length Sort data Sort alg User time
stdin 10000 random_list sort 2.82
stdin 10000 random_list mergesort 2.96
stdin 10000 sorted sort 31.37
stdin 10000 sorted mergesort 1.90
stdin 10000 revsorted sort 31.21
stdin 10000 revsorted mergesort 1.88
stdin 100000 random_list sort *
stdin 100000 random_list mergesort *
stdin 100000 sorted sort *
stdin 100000 sorted mergesort *
stdin 100000 revsorted sort *
stdin 100000 revsorted mergesort *
func 10000 random_list sort 0.31
func 10000 random_list mergesort 0.91
func 10000 sorted sort 19.09
func 10000 sorted mergesort 0.15
func 10000 revsorted sort 19.17
func 10000 revsorted mergesort 0.16
func 100000 random_list sort 3.85
func 100000 random_list mergesort *
func 100000 sorted sort 5831.47
func 100000 sorted mergesort 2.23
func 100000 revsorted sort 5872.34
func 100000 revsorted mergesort 2.24
- 결과 데이터를 보면 알 수 있듯이 비슷하거나 병합정렬이 더 빠르게 수행되었다.
- 놀랍게도 위에서 lan이라는 사람이 만든 병합정렬은 추후 2배 더 빠르게 변경되었다고 한다.
참고
https://hackage.haskell.org/package/base-4.11.1.0/docs/src/Data.OldList.html#sort
hackage.haskell.org
[알고리즘] 퀵 정렬 - Quick Sort (Python, Java)
Engineering Blog by Dale Seo
www.daleseo.com
Why does Haskell use mergesort instead of quicksort?
In Wikibooks' Haskell, there is the following claim: Data.List offers a sort function for sorting lists. It does not use quicksort; rather, it uses an efficient implementation of an algorithm ca...
stackoverflow.com

'Computer Science > Algorithm' 카테고리의 다른 글
| <알고리즘> 퀵 소트 & 힙 소트 (0) | 2021.12.24 |
|---|---|
| <알고리즘> 삽입정렬과 병합정렬 (0) | 2021.12.20 |
| <알고리즘> 버블정렬과 선택정렬 (0) | 2021.02.03 |
| <알고리즘> 재귀 알고리즘 (1) (0) | 2020.11.29 |
| <알고리즘> 검색 알고리즘(2) (0) | 2020.11.08 |



